Project repo:
https://github.com/JiakaiW/quant_ph_citation_graph_for_LLM
A vision model trained on metadata-tagged videos thumbnails to predict video popularity. Explores MobileNetV3 fine-tuning, gradual unfreezing backbone and checkpoint management.
The dataset is ~209K images, 33GB from a video platform:
Validation loss:
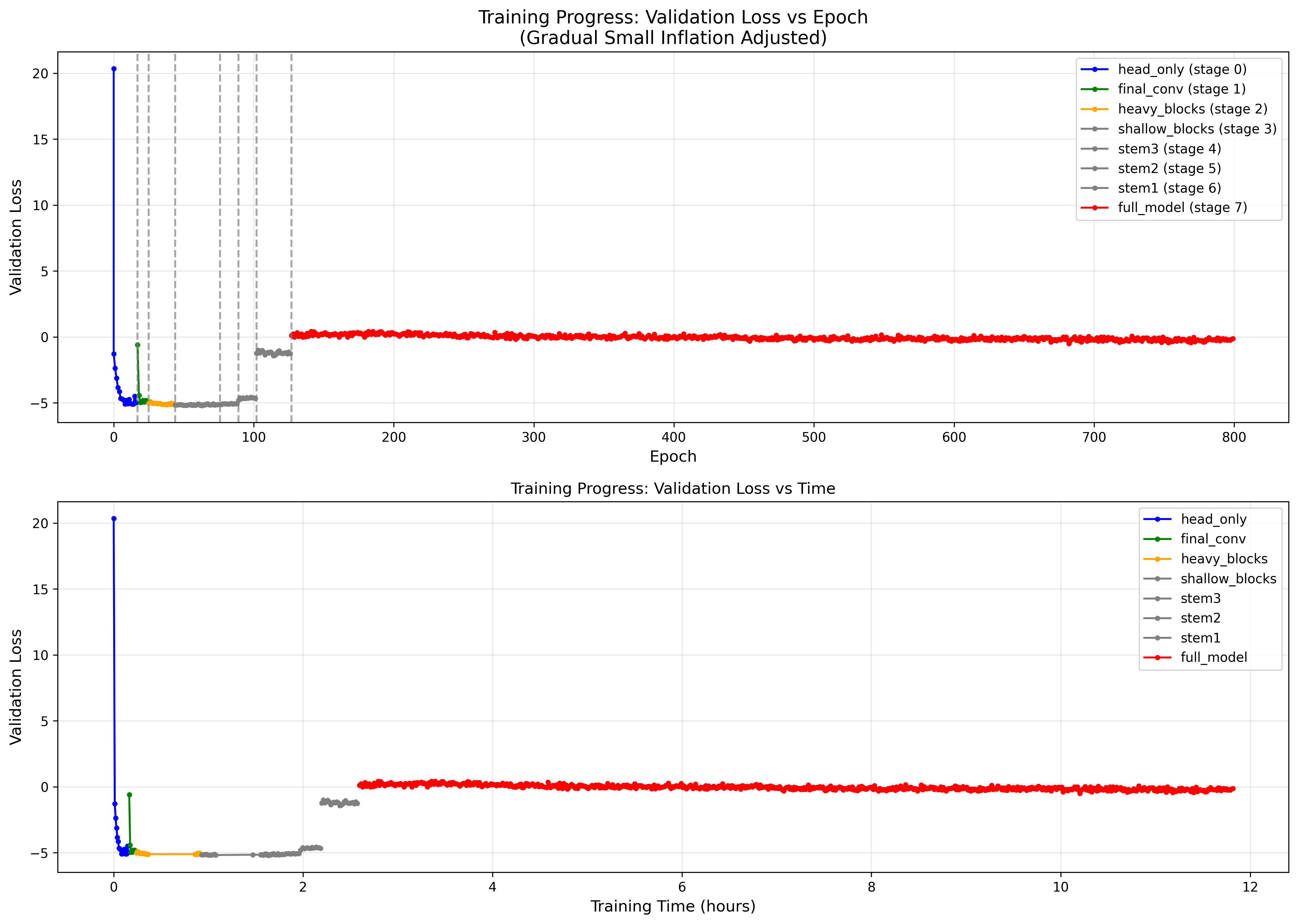
In this project I wrote some very OOC classes to interface with PyTorch lightening: ConfigReader, LearningManager (for learning rate), LossHistoryManager (contains logic about when to unfreeze next layer and gradual unfreezing), ModelCheckpointManager (custom file management) and CallBackManager (main interface with PyTorch lightening, dependency injection from the previous classes)
ConfigReader
class ConfigReader:
"""Base class for components that read configuration from config.yaml"""
def __init__(self, config_path: Optional[str] = None, verbose: bool = True):
self.verbose = verbose
self.config = load_training_config(config_path)
def get_config_value(self, key: str, default=None):
"""Get nested config value using dot notation"""
return get_config_value(self.config, key, default)
LearningManager
class LearningManager(ConfigReader):
"""Manages stage application, parameter freezing, learning rates, and regularization"""
def __init__(self, config_path: Optional[str] = None, verbose: bool = True):
super().__init__(config_path, verbose)
# Load learning configuration - ensure all values are converted to floats
self.base_weight_decay = float(self.get_config_value('optimization.weight_decay', 1e-4))
self.heavy_stage_weight_decay = float(self.get_config_value('learning.heavy_stage_weight_decay', 2e-4))
self.heavy_stage_dropout = float(self.get_config_value('learning.heavy_stage_dropout', 0.3))
self.normal_dropout = float(self.get_config_value('model.dropout_rate', 0.2))
def apply_stage(self, trainer: pl.Trainer, pl_module: pl.LightningModule, stage_config: Dict[str, Any], epochs_in_stage: int = 0):
"""Apply stage configuration: freeze/unfreeze parameters, update learning rates"""
stage_name = stage_config['name']
unfreeze_from_stage = stage_config['unfreeze_from_stage']
learning_rates = stage_config.get('learning_rates', {})
# Store epochs in stage for warm-up calculations
self._epochs_in_current_stage = epochs_in_stage
# Extract backbone LR early for freeze logic
backbone_lr = float(learning_rates.get('backbone', 0.0))
if self.verbose:
print(f"🔄 Applying stage: {stage_name} (epoch {epochs_in_stage+1} in stage)")
# MobileNetV3-Small stages for gradual unfreezing
backbone_stages = [
'features.0', 'features.1', 'features.2', 'features.3', 'features.4',
'features.5', 'features.6', 'features.7', 'features.8', 'features.9',
'features.10', 'features.11', 'features.12', 'classifier'
]
# Freeze all then unfreeze requested stages
for param in pl_module.model.parameters():
param.requires_grad = False
# THEORY FIX: Freeze classifier for first few epochs when backbone starts training
classifier_freeze_epochs = 3
freeze_classifier = (backbone_lr > 0 and epochs_in_stage < classifier_freeze_epochs and
stage_name != "head_only")
unfrozen_params = 0
unfrozen_layers = []
for i in range(unfreeze_from_stage, len(backbone_stages)):
stage_prefix = backbone_stages[i]
for name, param in pl_module.model.named_parameters():
# Skip classifier if we're in freeze period
if freeze_classifier and stage_prefix == 'classifier':
continue
if (stage_prefix == 'classifier' and name.startswith('classifier')) or \
(stage_prefix != 'classifier' and name.startswith(stage_prefix)):
param.requires_grad = True
unfrozen_params += param.numel()
unfrozen_layers.append(name)
if self.verbose:
if freeze_classifier:
print(f" 🧊 TEMPORARILY FREEZING CLASSIFIER (epoch {epochs_in_stage+1}/{classifier_freeze_epochs})")
print(f" 🔓 Unfrozen layers: {unfrozen_layers[:5]}{'...' if len(unfrozen_layers) > 5 else ''} ({len(unfrozen_layers)} total)")
# Freeze BatchNorm selectively - only freeze BN in frozen parts
self._freeze_bn_selectively(pl_module.model, backbone_stages, unfreeze_from_stage, freeze_classifier)
# Update learning rates (with warm-up awareness)
self._update_learning_rates(trainer, learning_rates, freeze_classifier)
# AGGRESSIVE FIX: Reset optimizer state when unfreezing new backbone layers
if backbone_lr > 0 and epochs_in_stage == 0: # First epoch of a stage with backbone training
self._reset_optimizer_state(trainer, stage_name)
# Apply overfitting fixes for later stages
self._apply_overfitting_fixes(trainer, pl_module, stage_config)
total_params = sum(p.numel() for p in pl_module.model.parameters())
unfrozen_pct = (unfrozen_params / total_params) * 100
if self.verbose:
print(f" 🧊 Unfrozen: {unfrozen_params:,} / {total_params:,} params ({unfrozen_pct:.1f}%)")
def _freeze_bn_selectively(self, model: nn.Module, backbone_stages: List[str], unfreeze_from_stage: int, freeze_classifier: bool = False):
"""
Freeze BatchNorm layers selectively based on which stages are unfrozen.
- Frozen stages: BN in eval() mode with frozen statistics
- Unfrozen stages: BN in train() mode but with frozen γ/β parameters
"""
# Determine which stages are unfrozen
unfrozen_stages = set(backbone_stages[unfreeze_from_stage:])
# If temporarily freezing classifier, remove it from unfrozen stages
if freeze_classifier:
unfrozen_stages.discard('classifier')
frozen_bn_count = 0
unfrozen_bn_count = 0
for name, module in model.named_modules():
if isinstance(module, (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d)):
# Check if this BN layer is in an unfrozen stage
is_in_unfrozen_stage = False
for stage_prefix in unfrozen_stages:
if stage_prefix == 'classifier' and name.startswith('classifier'):
is_in_unfrozen_stage = True
break
elif stage_prefix != 'classifier' and name.startswith(stage_prefix):
is_in_unfrozen_stage = True
break
if is_in_unfrozen_stage:
# Unfrozen stage: allow statistics to update but freeze learnable parameters
module.train()
for param in module.parameters():
param.requires_grad = False
unfrozen_bn_count += 1
else:
# Frozen stage: freeze everything including statistics
module.eval()
for param in module.parameters():
param.requires_grad = False
frozen_bn_count += 1
if self.verbose:
print(f" ❄️ BatchNorm: {frozen_bn_count} frozen (eval), {unfrozen_bn_count} unfrozen (train stats)")
effective_stages = list(unfrozen_stages)
if freeze_classifier:
effective_stages.append("classifier (temp frozen)")
print(f" 📋 Effective unfrozen stages: {effective_stages}")
def _reset_optimizer_state(self, trainer: pl.Trainer, stage_name: str):
"""Reset optimizer state (momentum, etc.) when transitioning to new stage"""
optimizer = trainer.optimizers[0]
# Reset state for all parameter groups
optimizer.state.clear()
# NUCLEAR OPTION: Reset scheduler state too
if hasattr(trainer, 'lr_schedulers') and trainer.lr_schedulers:
for scheduler_config in trainer.lr_schedulers:
scheduler = scheduler_config['scheduler']
if hasattr(scheduler, 'last_epoch'):
scheduler.last_epoch = -1 # Reset scheduler
if self.verbose:
print(f" 🔄 RESET scheduler state")
if self.verbose:
print(f" 🔄 RESET optimizer + scheduler state for stage transition to {stage_name}")
def _update_learning_rates(self, trainer: pl.Trainer, learning_rates: Dict[str, float], freeze_classifier: bool = False):
"""Update learning rates for parameter groups with optional warm-up for stage transitions"""
optimizer = trainer.optimizers[0]
head_lr = float(learning_rates.get('head', 1e-3))
backbone_lr = float(learning_rates.get('backbone', 1e-4))
# If classifier is frozen, set head LR to 0
if freeze_classifier:
head_lr = 0.0
# Apply warm-up for backbone when transitioning to new stages (first 3 epochs)
current_epoch = trainer.current_epoch
epochs_in_stage = getattr(self, '_epochs_in_current_stage', 0)
# DEBUG: Print detailed info
if self.verbose:
print(f" 🐛 DEBUG: current_epoch={current_epoch}, epochs_in_stage={epochs_in_stage}, backbone_lr={backbone_lr:.1e}")
if backbone_lr > 0 and epochs_in_stage < 3: # Warm-up for first 3 epochs of new stage
warmup_factor = (epochs_in_stage + 1) / 3.0 # Gradual ramp: 0.33, 0.67, 1.0
backbone_lr_warmed = backbone_lr * warmup_factor
if self.verbose:
print(f" 🔥 Backbone LR warm-up: {backbone_lr_warmed:.1e} (epoch {epochs_in_stage+1}/3, factor={warmup_factor:.2f})")
else:
backbone_lr_warmed = backbone_lr
if self.verbose and backbone_lr > 0:
print(f" 🔥 No warm-up needed: epochs_in_stage={epochs_in_stage} >= 3")
for group in optimizer.param_groups:
if group.get('name') == 'head':
group['lr'] = head_lr
elif group.get('name') == 'backbone':
group['lr'] = backbone_lr_warmed
if self.verbose:
if freeze_classifier:
print(f" 📈 Learning rates: head=0.0 (frozen), backbone={backbone_lr_warmed:.1e}")
elif backbone_lr_warmed != backbone_lr:
print(f" 📈 Learning rates: head={head_lr:.1e}, backbone={backbone_lr_warmed:.1e} (warmed from {backbone_lr:.1e})")
else:
print(f" 📈 Learning rates: head={head_lr:.1e}, backbone={backbone_lr:.1e}")
def _apply_overfitting_fixes(self, trainer: pl.Trainer, pl_module: pl.LightningModule, stage_config: Dict[str, Any]):
"""Apply regularization fixes for later stages"""
stage_name = stage_config['name']
optimizer = trainer.optimizers[0]
if stage_name in ["heavy_blocks", "full_model"]:
# Increase dropout and weight decay for later stages
if hasattr(pl_module.model, 'classifier'):
for layer in pl_module.model.classifier:
if hasattr(layer, 'p'):
layer.p = self.heavy_stage_dropout
break
for group in optimizer.param_groups:
group['weight_decay'] = self.heavy_stage_weight_decay
if self.verbose:
print(f" 🎯 Applied regularization for {stage_name} (dropout={self.heavy_stage_dropout}, wd={self.heavy_stage_weight_decay})")
else:
# Reset to normal values
if hasattr(pl_module.model, 'classifier'):
for layer in pl_module.model.classifier:
if hasattr(layer, 'p'):
layer.p = self.normal_dropout
break
for group in optimizer.param_groups:
group['weight_decay'] = self.base_weight_decay
LossHistoryManager
class LossHistoryManager(ConfigReader):
"""Centralized manager for training state, loss history, stage transitions, and early stopping"""
def __init__(
self,
stages: List[Dict[str, Any]],
checkpoint_dir: Path,
training_log_path: Path,
config_path: Optional[str] = None,
verbose: bool = True
):
super().__init__(config_path, verbose)
self.stages = stages
self.checkpoint_dir = checkpoint_dir
self.training_log = training_log_path
# Load loss history configuration - ensure numeric values are converted to proper types
self.plateau_patience = int(self.get_config_value('loss_history.plateau_patience', 5))
self.plateau_threshold = float(self.get_config_value('loss_history.plateau_threshold', 0.005))
self.head_only_patience = int(self.get_config_value('loss_history.head_only_patience', 8))
self.head_only_threshold = float(self.get_config_value('loss_history.head_only_threshold', 0.002))
# Early stopping parameters
self.early_stopping_patience = int(self.get_config_value('loss_history.early_stopping.patience', 15))
self.early_stopping_min_delta = float(self.get_config_value('loss_history.early_stopping.min_delta', 0.001))
self.early_stopping_mode = self.get_config_value('loss_history.early_stopping.mode', 'min')
# State tracking
self.current_stage_idx = 0
self.epochs_in_current_stage = 0
self.val_loss_history = []
self.is_resuming = False
self.stage_transition_checkpoint = None # Best checkpoint to restore on stage transition
# Early stopping state (only used in final stage)
self.should_stop_training = False
def load_from_csv(self):
"""Load training history from CSV and determine current state"""
# Prevent double loading
if hasattr(self, '_csv_loaded') and self._csv_loaded:
return
entries = self._read_training_log()
if not entries:
if self.verbose:
print("🆕 No training history found, starting fresh")
self._csv_loaded = True
return
# Find current stage from last entry
last_entry = entries[-1]
self.current_stage_idx = last_entry['stage_idx']
self.is_resuming = True
# Rebuild state from all entries
self._rebuild_state_from_entries(entries)
# Check if we should advance based on current state (unified logic)
if self.should_advance_stage():
self._prepare_stage_transition()
# Mark as loaded
self._csv_loaded = True
if self.verbose:
current_stage = self.stages[self.current_stage_idx]
print(f"🔄 Resumed: Stage {current_stage['name']} ({self.current_stage_idx + 1}/{len(self.stages)})")
print(f" 📊 {self.epochs_in_current_stage} epochs, best loss: {min(self.val_loss_history):.4f}")
print(f" 📈 Loss history length: {len(self.val_loss_history)}")
if self.stage_transition_checkpoint:
print(f" 🚀 Will transition to next stage using: {self.stage_transition_checkpoint.name}")
def update_loss_history(self, epoch: int, val_loss: float, checkpoint_path: str):
"""Update loss history, check early stopping, and log to CSV"""
current_stage = self.stages[self.current_stage_idx]
# Update internal state
self.val_loss_history.append(val_loss)
# Check early stopping (only in final stage)
if self.is_final_stage():
self._check_early_stopping(val_loss)
# Ensure we have a valid checkpoint path before logging
if not checkpoint_path or checkpoint_path == "":
# Try to construct the expected checkpoint path based on our naming convention
current_stage = self.stages[self.current_stage_idx]
expected_filename = f"stage-{current_stage['name']}_epoch-" + "{epoch:03d}" + "_val_loss-" + "{val_loss:.4f}" + ".ckpt"
checkpoint_path = expected_filename
if self.verbose:
print(f" ⚠️ No checkpoint path provided, using expected: {checkpoint_path}")
# Log to CSV
self._write_training_log_entry(epoch, current_stage['name'], self.current_stage_idx, val_loss, checkpoint_path)
if self.verbose:
print(f"📝 Logged: Epoch {epoch}, Stage {current_stage['name']}, Loss {val_loss:.4f}")
def should_advance_stage(self) -> bool:
"""
Simple plateau detection: advance if last n losses are all greater than the best (smallest) loss in current stage.
This indicates the model has passed its optimal point and is plateauing or getting worse.
"""
# Can't advance from final stage
if self.current_stage_idx >= len(self.stages) - 1:
return False
current_stage = self.stages[self.current_stage_idx]
is_head_only = current_stage['name'] == "head_only"
# Stage-specific parameters
if is_head_only:
plateau_check_epochs = self.head_only_patience # Check last n epochs
else:
plateau_check_epochs = self.plateau_patience # Check last n epochs
# Need minimum epochs before considering advancement
if self.epochs_in_current_stage < plateau_check_epochs:
if self.verbose and self.epochs_in_current_stage > 0: # Avoid spam on first epoch
remaining = plateau_check_epochs - self.epochs_in_current_stage
print(f" ⏳ Need {remaining} more epochs before stage advancement check")
return False
# Simple plateau detection: check if last n losses are all greater than the best (smallest) loss
best_loss = min(self.val_loss_history)
# Handle edge case: if we have fewer epochs than plateau_check_epochs, use what we have
check_epochs = min(plateau_check_epochs, len(self.val_loss_history))
recent_losses = self.val_loss_history[-check_epochs:]
# Check if all recent losses are worse than the best loss (indicating we've passed optimal point)
all_above_best = all(loss > best_loss for loss in recent_losses)
if all_above_best:
if self.verbose:
current_loss = self.val_loss_history[-1]
print(f" 📉 Plateau detected: last {check_epochs} losses all above best ({best_loss:.4f})")
print(f" Current loss: {current_loss:.4f}, Best loss: {best_loss:.4f}")
return True
# No advancement needed
if self.verbose:
current_loss = self.val_loss_history[-1]
above_best_count = sum(1 for loss in recent_losses if loss > best_loss)
print(f" 📈 Stage {current_stage['name']}: {self.epochs_in_current_stage} epochs, {above_best_count}/{check_epochs} recent losses above best")
print(f" Current: {current_loss:.4f}, Best: {best_loss:.4f}")
return False
def advance_to_next_stage(self) -> Optional[Path]:
"""Advance to next stage and return best checkpoint to restore"""
if self.current_stage_idx >= len(self.stages) - 1:
return None
current_stage = self.stages[self.current_stage_idx]
best_checkpoint = self._get_best_checkpoint_in_stage(current_stage['name'])
# Advance stage
self.current_stage_idx += 1
next_stage = self.stages[self.current_stage_idx]
# Reset state for new stage
self.epochs_in_current_stage = 0
self.val_loss_history = []
if self.verbose:
print(f"🚀 Stage transition: {current_stage['name']} → {next_stage['name']}")
if best_checkpoint:
print(f" 🏆 Using best checkpoint: {best_checkpoint.name}")
else:
print(f" ⚠️ No checkpoint available for stage transition, continuing with current weights")
return best_checkpoint
def get_current_stage(self) -> Dict[str, Any]:
"""Get current stage configuration"""
return self.stages[self.current_stage_idx]
def is_final_stage(self) -> bool:
"""Check if we're in the final stage"""
return self.current_stage_idx >= len(self.stages) - 1
def increment_epoch_count(self):
"""Increment epoch count for current stage"""
self.epochs_in_current_stage += 1
def get_stage_transition_checkpoint(self) -> Optional[Path]:
"""Get checkpoint to restore for stage transition (set during resume)"""
checkpoint = self.stage_transition_checkpoint
self.stage_transition_checkpoint = None # Clear after use
return checkpoint
def should_stop_early(self) -> bool:
"""Check if training should stop early"""
return self.should_stop_training
def _rebuild_state_from_entries(self, entries: List[Dict[str, Any]]):
"""Rebuild training state from CSV entries - single source of truth"""
if not entries:
return
# Get current stage name from last entry
last_entry = entries[-1]
current_stage_name = last_entry['stage_name']
# Filter entries for current stage only
current_stage_entries = [e for e in entries if e['stage_name'] == current_stage_name]
# Rebuild state from current stage entries
self.epochs_in_current_stage = len(current_stage_entries)
self.val_loss_history = [e['val_loss'] for e in current_stage_entries]
if self.verbose:
print(f" 📂 Rebuilt state from {len(entries)} total entries ({len(current_stage_entries)} in current stage)")
if current_stage_entries:
current_loss = self.val_loss_history[-1]
best_loss = min(self.val_loss_history)
max_loss = max(self.val_loss_history)
print(f" 📊 Current stage: {current_stage_name}")
print(f" Current: {current_loss:.4f}, Best: {best_loss:.4f}, Max: {max_loss:.4f}")
def _prepare_stage_transition(self):
"""Prepare for stage transition by finding best checkpoint"""
current_stage = self.stages[self.current_stage_idx]
self.stage_transition_checkpoint = self._get_best_checkpoint_in_stage(current_stage['name'])
# Advance stage index for resume
self.current_stage_idx += 1
self.epochs_in_current_stage = 0
self.val_loss_history = []
def _get_best_checkpoint_in_stage(self, stage_name: str) -> Optional[Path]:
"""Find best checkpoint file for a given stage"""
entries = self._read_training_log()
stage_entries = [e for e in entries if e['stage_name'] == stage_name]
if not stage_entries:
if self.verbose:
print(f" ⚠️ No training log entries found for stage: {stage_name}")
return None
best_entry = min(stage_entries, key=lambda x: x['val_loss'])
checkpoint_path_str = best_entry['checkpoint_path']
# Handle empty or invalid checkpoint paths
if not checkpoint_path_str or checkpoint_path_str == "" or checkpoint_path_str == ".":
if self.verbose:
print(f" ⚠️ Invalid checkpoint path in log for stage {stage_name}: '{checkpoint_path_str}'")
return None
checkpoint_path = Path(checkpoint_path_str)
if checkpoint_path.exists():
return checkpoint_path
else:
if self.verbose:
print(f" ⚠️ Best checkpoint for stage {stage_name} not found: {checkpoint_path}")
return None
def _read_training_log(self) -> List[Dict[str, Any]]:
"""Read training log CSV file"""
if not self.training_log.exists():
return []
import csv
entries = []
try:
with open(self.training_log, 'r') as f:
reader = csv.DictReader(f)
for row in reader:
row['epoch'] = int(row['epoch'])
row['stage_idx'] = int(row['stage_idx'])
row['val_loss'] = float(row['val_loss'])
entries.append(row)
except Exception as e:
if self.verbose:
print(f"⚠️ Failed to read training log: {e}")
return []
return entries
def _check_early_stopping(self, current_loss: float):
"""Simple early stopping: stop if recent losses don't improve beyond min_delta"""
if len(self.val_loss_history) < self.early_stopping_patience:
return # Need enough history
# Get recent losses for comparison
recent_losses = self.val_loss_history[-self.early_stopping_patience:]
best_recent = min(recent_losses)
# Check if current loss is not improving beyond min_delta from best recent
if current_loss > (best_recent - self.early_stopping_min_delta):
# No meaningful improvement in recent epochs
if self.verbose:
print(f" ⏳ Early stopping: no improvement > {self.early_stopping_min_delta:.4f} in last {self.early_stopping_patience} epochs")
print(f" Current: {current_loss:.4f}, Best recent: {best_recent:.4f}")
# Simple check: if all recent losses are very similar, stop
loss_range = max(recent_losses) - min(recent_losses)
if loss_range < self.early_stopping_min_delta:
self.should_stop_training = True
if self.verbose:
print(f"🛑 Early stopping triggered - loss plateau detected")
print(f" 📊 Loss range in last {self.early_stopping_patience} epochs: {loss_range:.4f}")
def _write_training_log_entry(self, epoch: int, stage_name: str, stage_idx: int, val_loss: float, checkpoint_path: str):
"""Write single entry to training log"""
import csv
# Create header if file doesn't exist
if not self.training_log.exists():
with open(self.training_log, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['epoch', 'stage_name', 'stage_idx', 'val_loss', 'checkpoint_path', 'timestamp'])
# Append entry
with open(self.training_log, 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow([epoch, stage_name, stage_idx, val_loss, checkpoint_path, datetime.now().isoformat()])
ModelCheckpointManager
class ModelCheckpointManager(ConfigReader):
"""Manages checkpoint saving, loading, and file operations"""
def __init__(
self,
checkpoint_dir: Path,
config_path: Optional[str] = None,
verbose: bool = True
):
super().__init__(config_path, verbose)
self.checkpoint_dir = checkpoint_dir
# Load checkpointing configuration - ensure proper types
self.monitor = self.get_config_value('checkpointing.monitor', 'val_loss')
self.mode = self.get_config_value('checkpointing.mode', 'min')
self.save_top_k = int(self.get_config_value('checkpointing.save_top_k', -1))
self.every_n_epochs = int(self.get_config_value('checkpointing.every_n_epochs', 1))
self.save_last = bool(self.get_config_value('checkpointing.save_last', False))
self.internal_checkpoint_callback: Optional[ModelCheckpoint] = None
def setup_checkpoint_callback(self, trainer: pl.Trainer, stage_name: str):
"""Setup internal ModelCheckpoint callback for actual checkpoint saving"""
filename_template = f"stage-{stage_name}_epoch-" + "{epoch:03d}" + "_val_loss-" + "{val_loss:.4f}"
# Remove old callback if exists
if self.internal_checkpoint_callback in trainer.callbacks:
trainer.callbacks.remove(self.internal_checkpoint_callback)
self.internal_checkpoint_callback = ModelCheckpoint(
dirpath=str(self.checkpoint_dir),
filename=filename_template,
monitor=self.monitor,
mode=self.mode,
save_top_k=self.save_top_k,
every_n_epochs=self.every_n_epochs,
save_last=self.save_last,
auto_insert_metric_name=False,
)
trainer.callbacks.append(self.internal_checkpoint_callback)
def get_last_checkpoint_path(self) -> str:
"""Get the path of the last saved checkpoint"""
if self.internal_checkpoint_callback and self.internal_checkpoint_callback.last_model_path:
return self.internal_checkpoint_callback.last_model_path
return ""
def restore_checkpoint(self, trainer: pl.Trainer, pl_module: pl.LightningModule, checkpoint_path: Optional[Path]):
"""Restore checkpoint for stage transition"""
if checkpoint_path is None:
if self.verbose:
print(f" ⚠️ No checkpoint to restore (None provided)")
return
if not checkpoint_path.exists():
if self.verbose:
print(f" ⚠️ Checkpoint file does not exist: {checkpoint_path}")
return
try:
if self.verbose:
print(f" 🏆 Restoring checkpoint: {checkpoint_path.name}")
checkpoint = torch.load(checkpoint_path, map_location=pl_module.device, weights_only=False)
pl_module.load_state_dict(checkpoint['state_dict'])
if 'optimizer_states' in checkpoint and trainer.optimizers:
try:
trainer.optimizers[0].load_state_dict(checkpoint['optimizer_states'][0])
if self.verbose:
print(f" ✅ Restored model + optimizer state")
except Exception:
if self.verbose:
print(f" ✅ Restored model state only")
except Exception as e:
if self.verbose:
print(f" ❌ Failed to restore checkpoint: {e}")
def find_latest_checkpoint(self, experiment_dir: Optional[Path] = None) -> Optional[Path]:
"""Find the latest checkpoint in an experiment directory"""
if experiment_dir is None:
checkpoint_search_dir = self.checkpoint_dir
else:
# If experiment_dir is provided, look in its checkpoints subdirectory
checkpoint_search_dir = experiment_dir / "checkpoints" if (experiment_dir / "checkpoints").exists() else experiment_dir
if not checkpoint_search_dir.exists():
return None
# Look for last.ckpt first (most recent)
last_ckpt = checkpoint_search_dir / "last.ckpt"
if last_ckpt.exists():
return last_ckpt
# Otherwise find the highest epoch checkpoint by looking for stage-* patterns
stage_ckpts = list(checkpoint_search_dir.glob("stage-*.ckpt"))
if stage_ckpts:
def extract_epoch(path):
import re
match = re.search(r'epoch-(\d+)', path.name)
return int(match.group(1)) if match else 0
return sorted(stage_ckpts, key=extract_epoch)[-1]
# Fallback to epoch*.ckpt pattern
epoch_ckpts = list(checkpoint_search_dir.glob("epoch*.ckpt"))
if epoch_ckpts:
def extract_epoch(path):
import re
match = re.search(r'epoch(\d+)', path.name)
return int(match.group(1)) if match else 0
return sorted(epoch_ckpts, key=extract_epoch)[-1]
return None
CallBackManager
class CallBackManager(Callback):
"""
Overarching callback manager that orchestrates loss tracking, checkpointing, and learning management.
Coordinates between LossHistoryManager, ModelCheckpointManager, and LearningManager.
"""
def __init__(
self,
stages: List[Dict[str, Any]],
image_config: str = "small",
label_config: str = "inflation_adjusted",
checkpoints_root: Optional[str] = None,
force_new: bool = False,
resume_from: Optional[str] = None,
config_path: Optional[str] = None,
verbose: bool = True,
):
super().__init__()
self.stages = stages
self.image_config = image_config
self.label_config = label_config
self.force_new = force_new
self.resume_from = resume_from
self.config_path = config_path
self.verbose = verbose
# Setup experiment directory
self.experiment_dir = self._setup_experiment_directory(checkpoints_root)
self.experiment_dir.mkdir(parents=True, exist_ok=True)
# Create checkpoints subdirectory
self.checkpoint_dir = self.experiment_dir / "checkpoints"
self.checkpoint_dir.mkdir(parents=True, exist_ok=True)
# Initialize managers with config path
self.loss_history_manager = LossHistoryManager(
stages=stages,
checkpoint_dir=self.experiment_dir, # Use experiment dir for training log
training_log_path=self.experiment_dir / "training_log.csv",
config_path=config_path,
verbose=verbose
)
self.checkpoint_manager = ModelCheckpointManager(
checkpoint_dir=self.checkpoint_dir, # Use checkpoints subdir for actual checkpoints
config_path=config_path,
verbose=verbose
)
self.learning_manager = LearningManager(
config_path=config_path,
verbose=verbose
)
def setup(self, trainer: pl.Trainer, pl_module: pl.LightningModule, stage: str):
"""Setup callback with trainer"""
# Load training state from CSV
if not self.force_new and trainer.current_epoch == 0:
self.loss_history_manager.load_from_csv()
# Setup initial checkpoint callback
current_stage = self.loss_history_manager.get_current_stage()
self.checkpoint_manager.setup_checkpoint_callback(trainer, current_stage['name'])
if self.verbose:
print(f"📊 CallBack Manager")
print(f" Experiment: {self.experiment_dir}")
print(f" Checkpoints: {self.checkpoint_dir}")
print(f" Current Stage: {current_stage['name']} ({self.loss_history_manager.current_stage_idx + 1}/{len(self.stages)})")
print(f" Monitor: {self.checkpoint_manager.monitor}")
def on_train_epoch_start(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
"""Check for stage transitions and apply stage configuration"""
# Handle stage transition if needed (from resume)
transition_checkpoint = self.loss_history_manager.get_stage_transition_checkpoint()
if transition_checkpoint:
# Call restore_checkpoint - it will handle None gracefully
self.checkpoint_manager.restore_checkpoint(trainer, pl_module, transition_checkpoint)
current_stage = self.loss_history_manager.get_current_stage()
self.checkpoint_manager.setup_checkpoint_callback(trainer, current_stage['name'])
# Check if current stage should advance
if self.loss_history_manager.should_advance_stage():
best_checkpoint = self.loss_history_manager.advance_to_next_stage()
# Always call restore_checkpoint - it will handle None gracefully
self.checkpoint_manager.restore_checkpoint(trainer, pl_module, best_checkpoint)
current_stage = self.loss_history_manager.get_current_stage()
self.checkpoint_manager.setup_checkpoint_callback(trainer, current_stage['name'])
# Apply current stage configuration
current_stage = self.loss_history_manager.get_current_stage()
epochs_in_stage = self.loss_history_manager.epochs_in_current_stage
self.learning_manager.apply_stage(trainer, pl_module, current_stage, epochs_in_stage)
def on_train_epoch_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
"""Called at the end of each training epoch"""
self.loss_history_manager.increment_epoch_count()
def on_validation_epoch_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
"""Update loss history, check early stopping, and log progress"""
monitor = self.checkpoint_manager.monitor
val_metric = trainer.callback_metrics.get(monitor)
if val_metric is None:
if self.verbose:
print(f"⚠️ Metric '{monitor}' not found in callback_metrics")
return
val_loss = float(val_metric)
# Get checkpoint path - need to wait a bit for ModelCheckpoint to save
checkpoint_path = self.checkpoint_manager.get_last_checkpoint_path()
# If no checkpoint path yet, construct expected one
if not checkpoint_path:
current_stage = self.loss_history_manager.get_current_stage()
expected_filename = f"stage-{current_stage['name']}_epoch-" + "{trainer.current_epoch:03d}" + "_val_loss-" + "{val_loss:.4f}" + ".ckpt"
checkpoint_path = str(self.checkpoint_dir / expected_filename)
# Update loss history manager (includes early stopping check)
self.loss_history_manager.update_loss_history(trainer.current_epoch, val_loss, checkpoint_path)
# Check if training should stop early
if self.loss_history_manager.should_stop_early():
trainer.should_stop = True
def get_current_stage(self) -> Dict[str, Any]:
"""Get current stage information"""
return self.loss_history_manager.get_current_stage()
def is_final_stage(self) -> bool:
"""Check if we're in the final stage"""
return self.loss_history_manager.is_final_stage()
def get_resume_checkpoint_path(self) -> Optional[Path]:
"""Get checkpoint path for resuming training"""
# If we haven't loaded from CSV yet and we're not forcing new, do it now
if not self.loss_history_manager.is_resuming and not self.force_new:
self.loss_history_manager.load_from_csv()
if self.loss_history_manager.is_resuming:
checkpoint_path = self.checkpoint_manager.find_latest_checkpoint()
if self.verbose and checkpoint_path:
print(f"📍 Found resume checkpoint: {checkpoint_path.name}")
return checkpoint_path
return None
def state_dict(self) -> Dict[str, Any]:
"""Return state dict for checkpoint saving"""
return {
'current_stage_idx': self.loss_history_manager.current_stage_idx,
'epochs_in_current_stage': self.loss_history_manager.epochs_in_current_stage,
'val_loss_history': self.loss_history_manager.val_loss_history[-10:], # Keep last 10 for reference
}
def load_state_dict(self, state_dict: Dict[str, Any]):
"""Load state dict from checkpoint"""
try:
self.loss_history_manager.current_stage_idx = state_dict.get('current_stage_idx', 0)
self.loss_history_manager.epochs_in_current_stage = state_dict.get('epochs_in_current_stage', 0)
self.loss_history_manager.val_loss_history = state_dict.get('val_loss_history', [])
except Exception as e:
if self.verbose:
print(f"⚠️ Failed to load state: {e}")
def _setup_experiment_directory(self, checkpoints_root: Optional[str]) -> Path:
"""Setup experiment directory with intelligent resume/new logic"""
if checkpoints_root is None:
try:
import sys
sys.path.append(str(Path(__file__).parent.parent))
from utils.config import get_config
app_config = get_config()
default_root = Path(app_config.get('directories.models', 'data/models/saved_models')).parent / "checkpoints"
except Exception:
default_root = Path("data/models/checkpoints")
checkpoints_root = str(default_root)
checkpoints_root = Path(checkpoints_root)
timestamp = datetime.now().strftime("%Y%m%d_%H%M")
if self.resume_from:
checkpoint_dir = checkpoints_root / self.resume_from
if not checkpoint_dir.exists():
raise ValueError(f"Resume directory not found: {checkpoint_dir}")
if self.verbose:
print(f"🔄 Resuming from: {self.resume_from}")
elif not self.force_new:
latest_experiment = self._find_latest_experiment(checkpoints_root)
if latest_experiment:
checkpoint_dir = latest_experiment
if self.verbose:
print(f"🔄 Auto-resuming from: {latest_experiment.name}")
else:
experiment_name = f"{timestamp}_gradual_{self.image_config}_{self.label_config}"
checkpoint_dir = checkpoints_root / experiment_name
if self.verbose:
print(f"🆕 Starting new experiment: {experiment_name}")
else:
experiment_name = f"{timestamp}_gradual_{self.image_config}_{self.label_config}"
checkpoint_dir = checkpoints_root / experiment_name
if self.verbose:
print(f"🚀 Force starting new experiment: {experiment_name}")
checkpoint_dir.mkdir(parents=True, exist_ok=True)
self._save_experiment_config(checkpoint_dir, timestamp)
if self.verbose:
print(f"💾 Experiment: {checkpoint_dir}")
return checkpoint_dir
def _find_latest_experiment(self, checkpoints_root: Path) -> Optional[Path]:
"""Find the most recent experiment directory for the given config"""
if not checkpoints_root.exists():
return None
pattern = f"*_gradual_{self.image_config}_{self.label_config}"
matching_dirs = list(checkpoints_root.glob(pattern))
if not matching_dirs:
return None
latest_dir = sorted(matching_dirs)[-1]
# Check if there are checkpoints in the checkpoints subdirectory or root
checkpoints_subdir = latest_dir / "checkpoints"
if checkpoints_subdir.exists():
checkpoints = list(checkpoints_subdir.glob("*.ckpt"))
if checkpoints:
return latest_dir
# Fallback: check for checkpoints in the root directory (old format)
checkpoints = list(latest_dir.glob("*.ckpt"))
if checkpoints:
return latest_dir
return None
def _save_experiment_config(self, checkpoint_dir: Path, timestamp: str):
"""Save experiment configuration for future reference"""
config_file = checkpoint_dir / "experiment_config.json"
config_data = {
'experiment_type': 'gradual_unfreezing_v2',
'image_config': self.image_config,
'label_config': self.label_config,
'stages': self.stages,
'pytorch_lightning_version': pl.__version__,
'timestamp': timestamp
}
with open(config_file, 'w') as f:
json.dump(config_data, f, indent=2, default=str)